Einleitung
Hyperkonvergente Systeme sind immer weiter im Trend und erobern auch die deutschen Rechenzentren. Eher neu ist die HCI Lösung von Microsoft: Azure Stack HCI, die (erst) seit Ende Dezember 2020 auf dem Markt ist. Hierbei handelt es sich um ein eigenes Betriebssystem (auf Basis von Server 2019) welches rein für die Hyper-V Dienste ausgelegt ist und sich funktional von den klassischen Windows-Server Varianten in Zukunft auf die Virtualisierung abheben soll. So gibt es Azure Stack HCI nur als Core-Installation (also ohne GUI) – die Bedienung soll per Windows Admin Center oder rein per Powershell erfolgen. Neu ist auch das Lizenzierungsmodell, wo Microsoft auf eine Gebühr von 10€/Monat pro CPU Kern veranschlagt. Hier möchte man anscheinend ähnlich der Konkurrenz auch am Hypervisor verdienen.
Da die Software relativ neu ist, findet man aktuell leider relativ schwer Benchmarks oder Performancedaten von Systemaufbauten, die nicht rein für Marketingzwecke ausgerichtet sind. Daher habe ich mich entschieden hier einige Ergebnisse als Orientierung zu präsentieren. Getestet wird ein für Azure Stack HCI zertifiziertes System von Dell in Form von AX-740XD Systemen, die nach Best-Practise konfiguriert wurden. Das Betriebssystem der Server war die zum Zeitpunkt aktuellste Azure Stack HCI Version. (Patchstand Mai 2021).
Hardwareaufbau
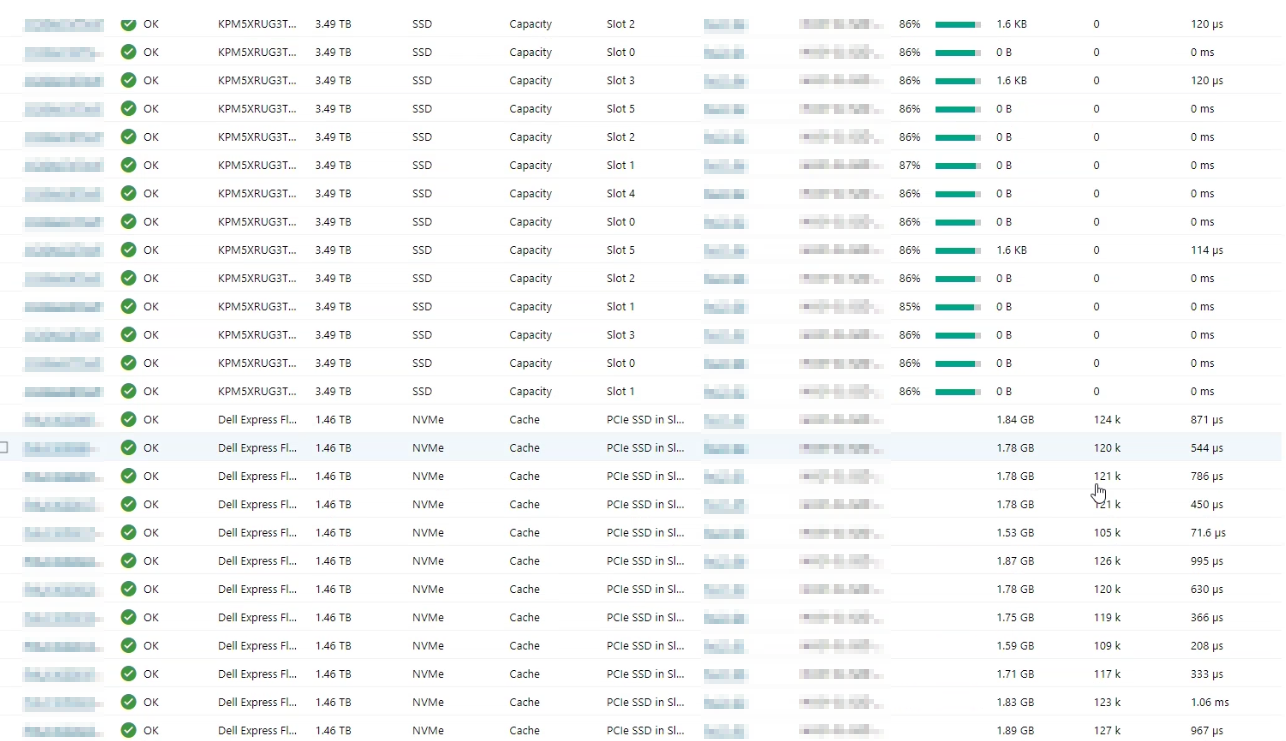
Als Aufbau dienen 6 Dell AX-740XD Server mit folgender SSD/Fullflash Konfiguration:
Für das OS werden die BOSS Karten verwendet. Als Cache Karten werden je 2 x NVME verwendet. Für den Kapazitäts-Tier werden je 6 x SSD verwendet.
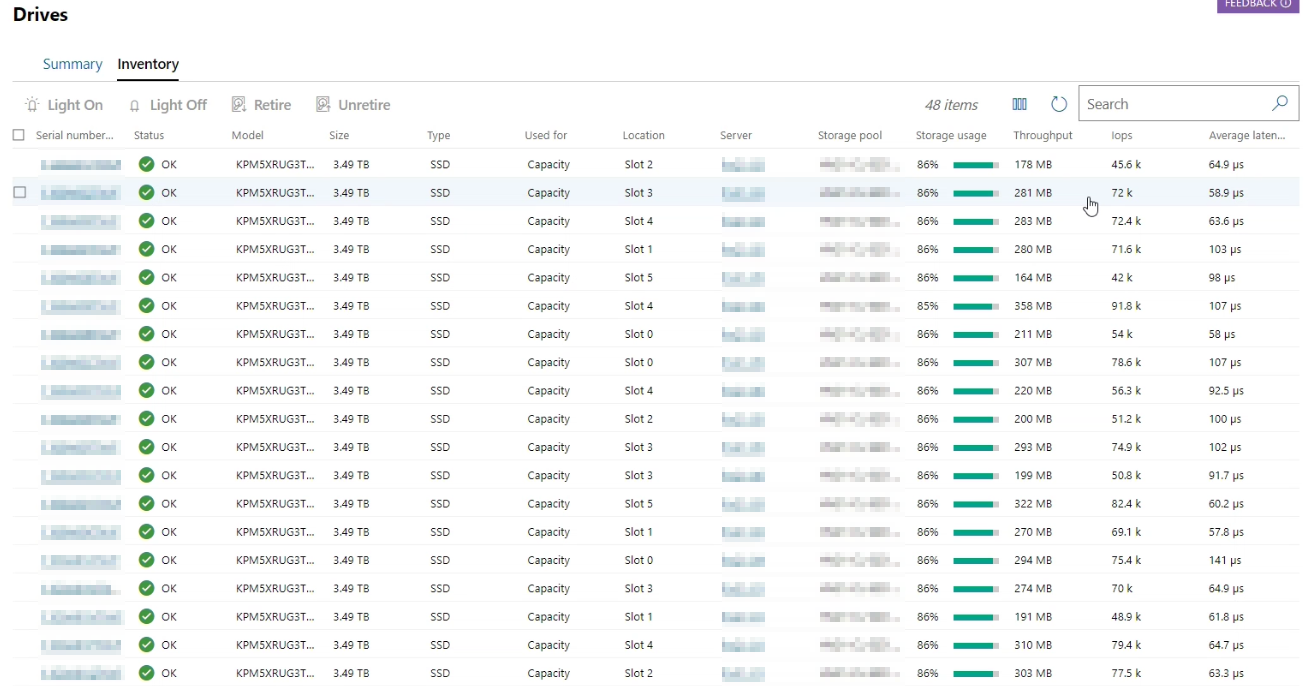
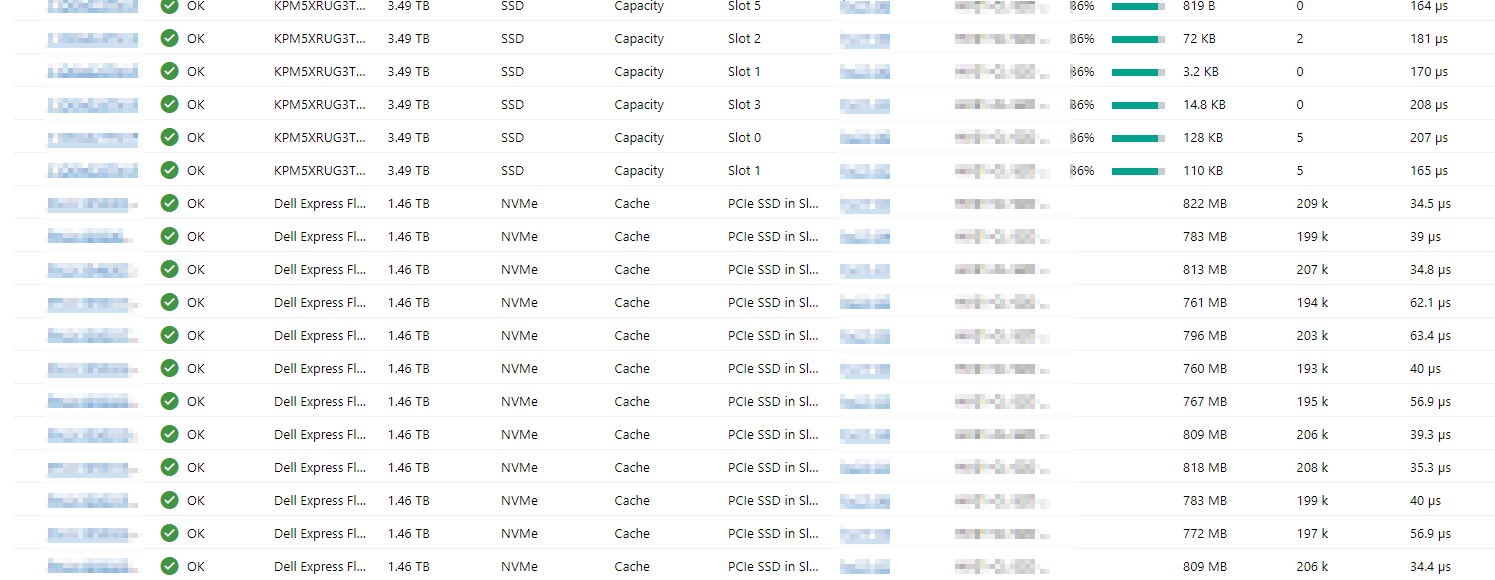
| MediaType | BusType | Usage | Model | FriendlyName | Kapazität | Anzahl Insgesamt | Anzahl pro Server |
| SSD | SATA | Boot-Drive | SSDSCKKB240G8R | DELLBOSS VD | 223.57 GB | 12 | 2 |
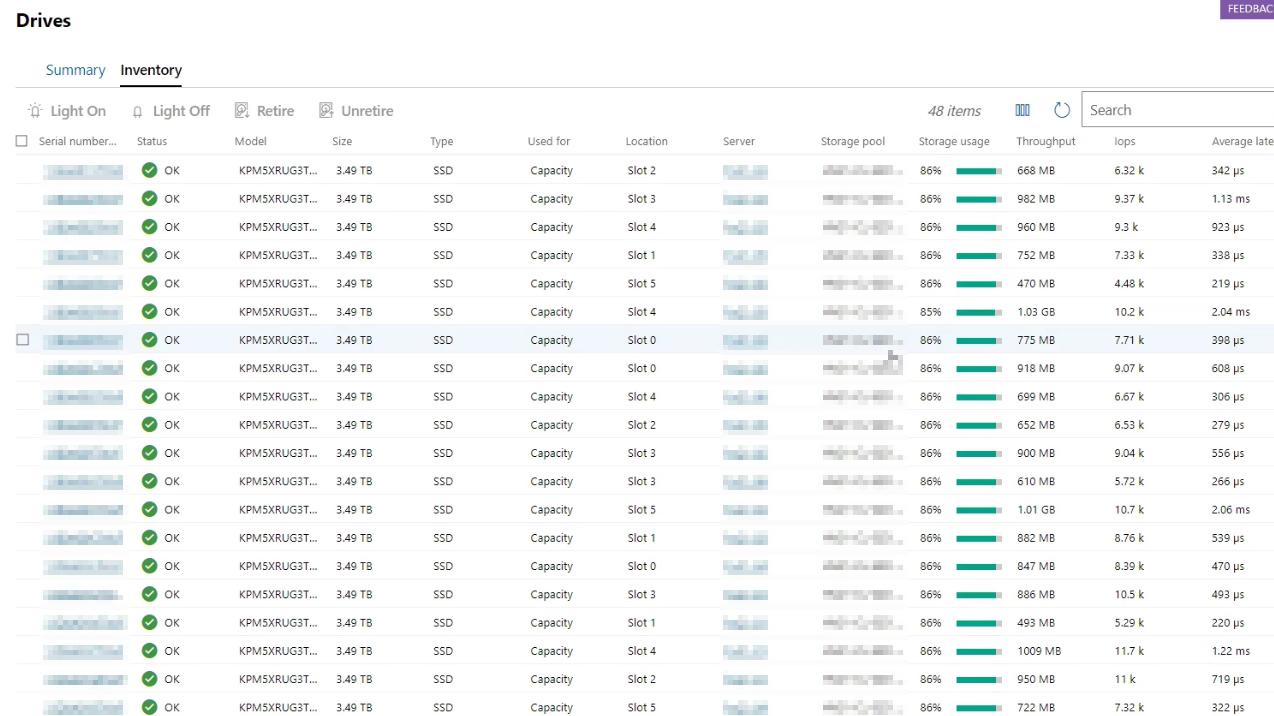
| SSD | SAS | Auto-Select (Capacity) | KPM5XRUG3T84 | TOSHIBA KPM5XRUG3T84 | 3.49 TB | 36 | 6 |
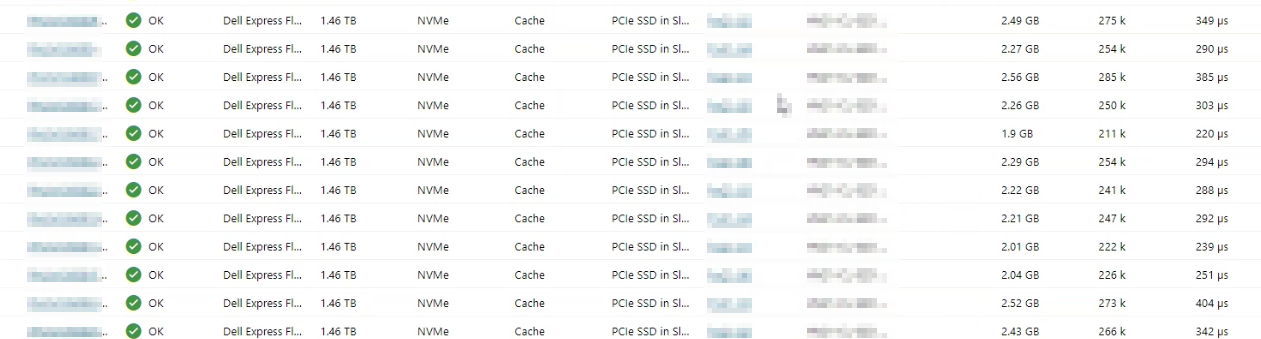
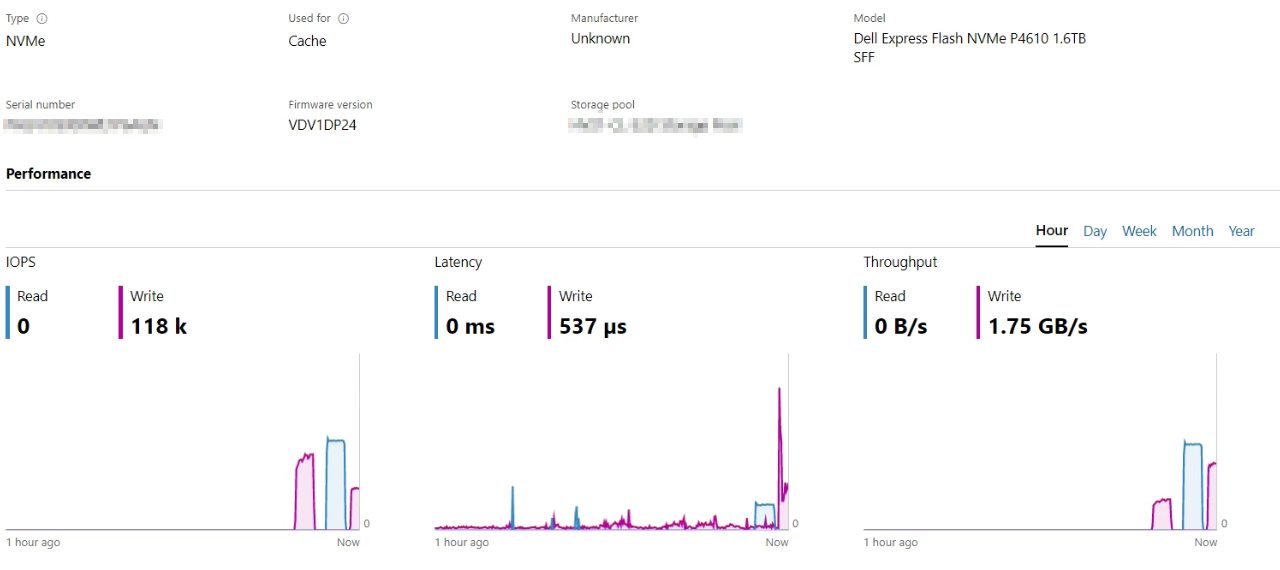
| SSD | PCIe | Journal (Cache) | Dell Express Flash NVMe P4610 1.6TB SFF | Dell Express Flash NVMe P4610 1.6TB SFF | 1.46 TB | 12 | 2 |
Herstellerangaben und theoretische max-Werte
Da es kaum Vergleichswerte bei solchen Systemen gibt, ziehen wir als Vergleich die Herstellerangaben heran. So haben wir zumindest einen Richtwert, der uns hilft das System zu validieren. Um nähere Spezifikationen zu den möglichen Schreib/Lesewerten und IOPS zu bekommen, müssen wir uns nun die Modelle etwas genauer anschauen. Die 3,49 TB SSD ist zwar laut Beschreibung von TOSHIBA – hinter dem Namen versteckt sich aber der Hersteller Kioxia und genau folgendes Modell: PM5-R Series. Auf der Herstellerseite finden wir dann auch Angaben zu den theoretischen Werten:
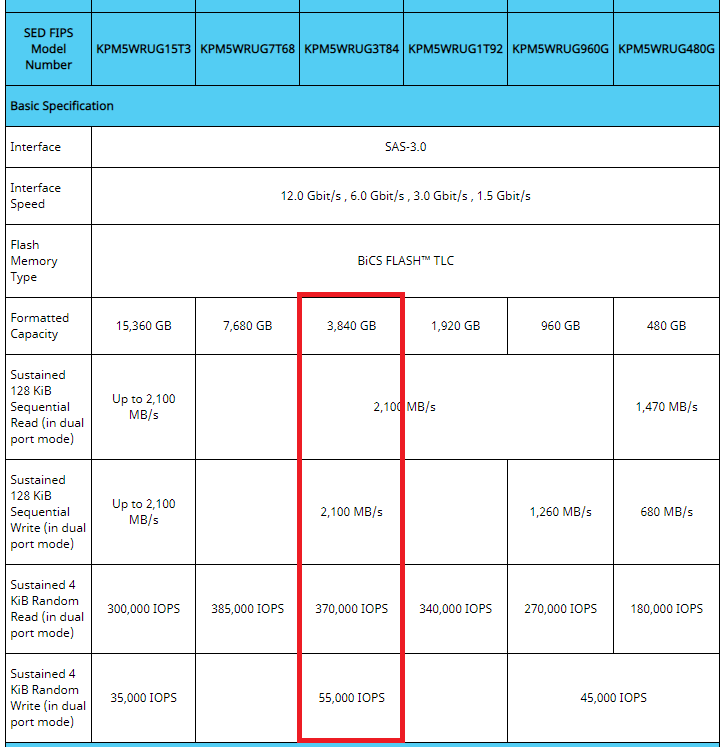
Man beachte, dass die Herstellerangaben unter Verwendung von Dual Port 12GB SAS gemessen wurde, was in unserem S2D/Azure Stack HCI Konstrukt nicht der Fall ist und die SSD „lediglich“ über einen SAS Port angeschlossen ist. Daher sind unsere Ergebnisse in der Praxis etwas geringer. Als einzelne SSD eingebunden und Formatiert mit 64k ReFS haben wir mit CrystalDiskMark für die KPM5XRUG3T84 folgende Werte erhalten:
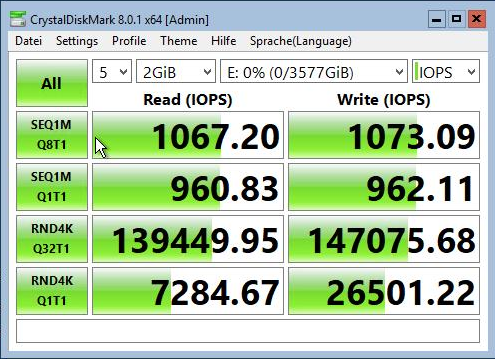
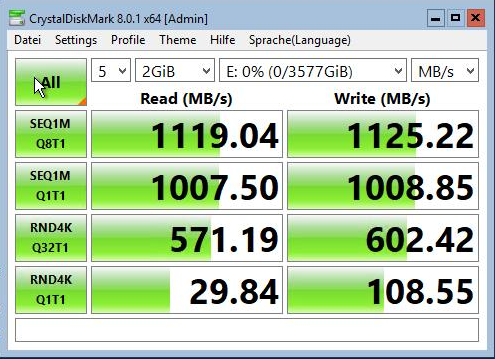
Für die P4610 von Dell finden wir direkt bei Dell in einem DataSheet die vergleichbaren Daten:
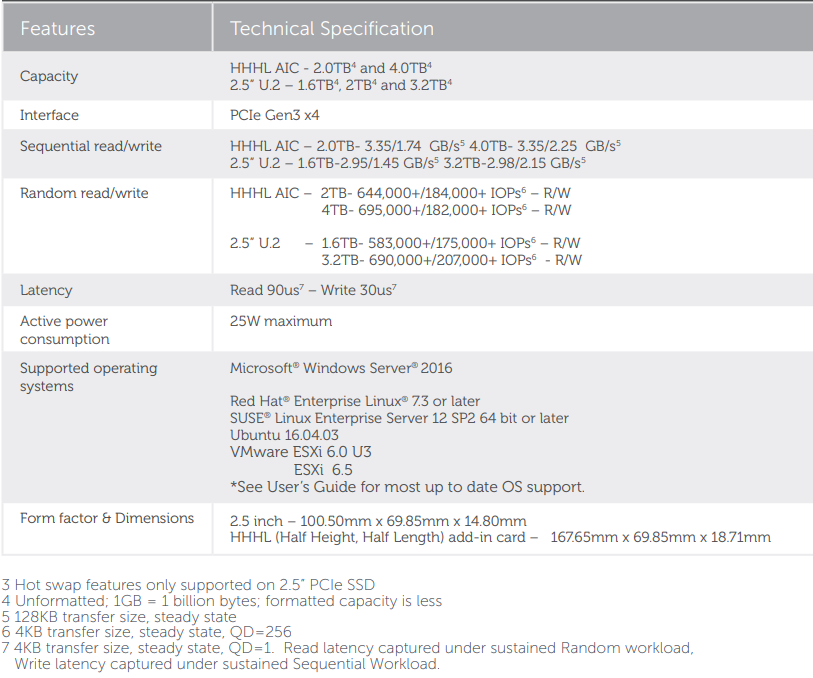
Netzwerk
Netzwerkseitig sind die Systeme mit 4 x 25GB über 2 Dual Port „Mellanox ConnectX-4 Lx 25GbE SFP28“ Karten mit je einem DELL SF5212F verbunden.
Als Technologie für die Storagereplikation verwenden wir RDMA.
Storageübersicht

In Summe haben wir einen Storagepool den wir auf 6 Volumes (1 pro Host) aufteilen. Für alle Volumes verwenden wir einen Three-Way-Mirror, für maximale Performance.

Testmöglichkeiten
Es gibt 2 verschiedene Testmöglichkeiten um den Cluster auf Herz und Iops zu testen.
VMFleet war früher das gängige Tool und es gibt dazu auch gute Beschreibungen wie von DataOn. Es ist etwas umständlich zu konfigurieren, aber hat es mehrere VM’s erzeugt und in diesen dann diskspd ausgeführt. Dies wäre meiner Ansicht nach zumindest ein Test wo der Realität am nächsten kommt. Laut Microsoft (Azure Stack HCI Support) ist VMFleet allerdings nicht mehr supported was Benchmarks angeht.
Präferierte Variante: StartWorkload.ps1
Hier muss lediglich DiskSpd heruntergeladen werden und keinerlei extra VM’s erzeugt werden. Das Tool verschiebt die ClusterStorage’s und verteilt diese auf die Hosts und startet dann DiskSpd auf jedem Host für sein Cluster-Volume.
Zu Beginn müssen wir erstmal 3 benötigte Tools herunterladen:
watch-cluster.ps1
start-workload.ps1
diskspd.exe
Alle Tools packen wir in einen Ordner, diskspd muss zuvor noch entpackt werden.
Watch-Cluster
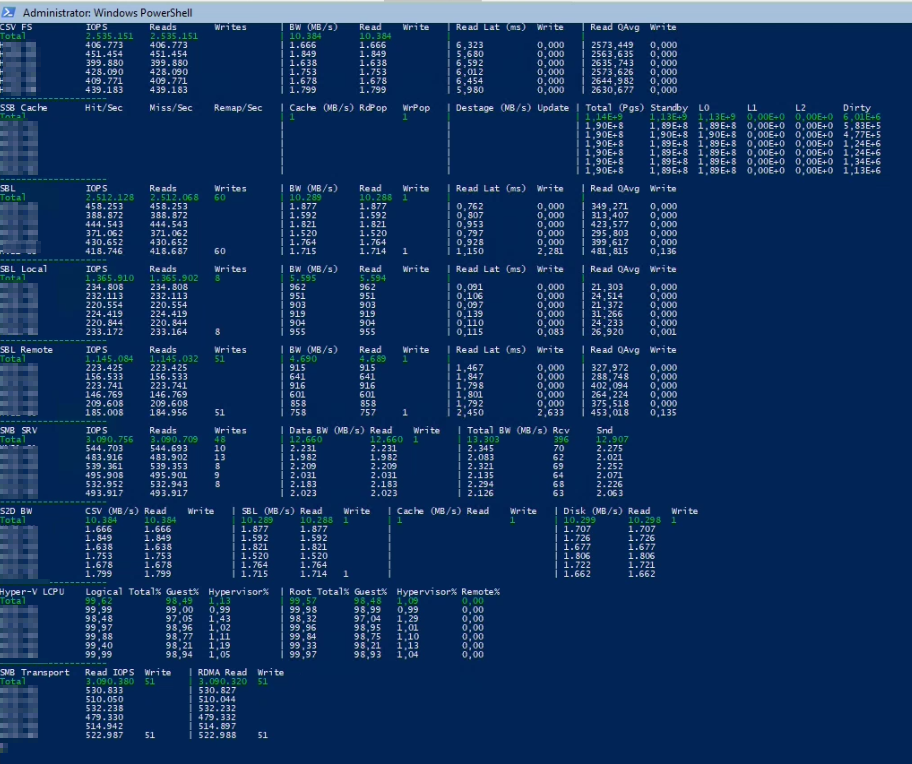
In einem Powershellfenster auf dem Host starten wir Watch-Cluster, welches uns die Storagewerte live liefert. Das Tool ist deutlich genauer als z.B. das Windows Admin Center.
Um alle Daten in einem Fenster angezeigt zu bekommen muss man in der Regel die Schriftgröße des Powershellfensters auf 10 oder 11 herabsetzen 🙂
.\watch-cluster.ps1 -sets *
Start-Workload
Mit Start-Workload können wir nun verschiedene Szenarien durchprobieren. Wenn man diese aufzeichnen möchte, lohnt sich ggf. auch die Aufnahme der Performancecounter .
4K 100% Read with minimal Latency to identify if we have a latency issue
.\Start-Workload.ps1 -DiskSpdpath "C:\Temp\Diskspd.exe"
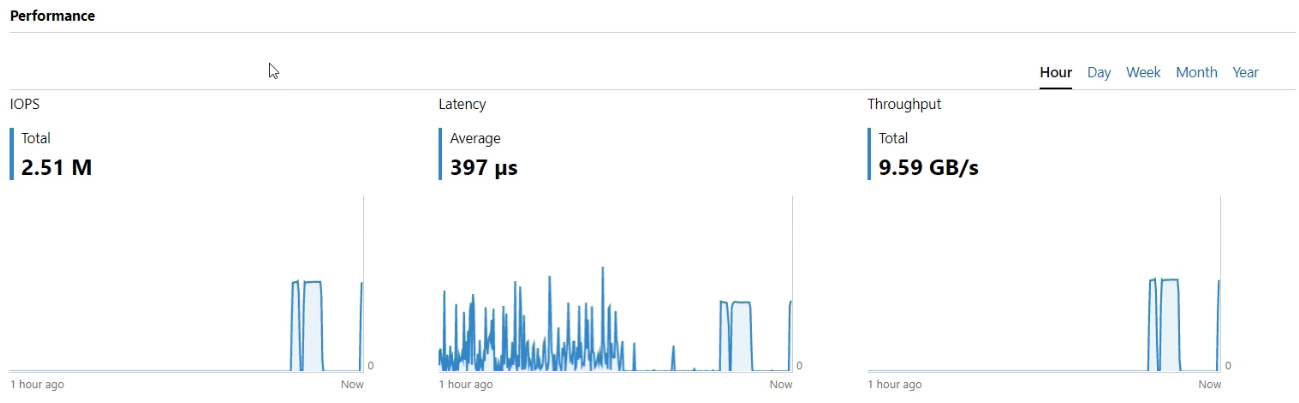

4K 100% Read (Maximize IOPS), we don’t care too much about Latency:
.\Start-Workload.ps1 -DiskSpdpath "C:\Temp\DiskSpd" -o 32
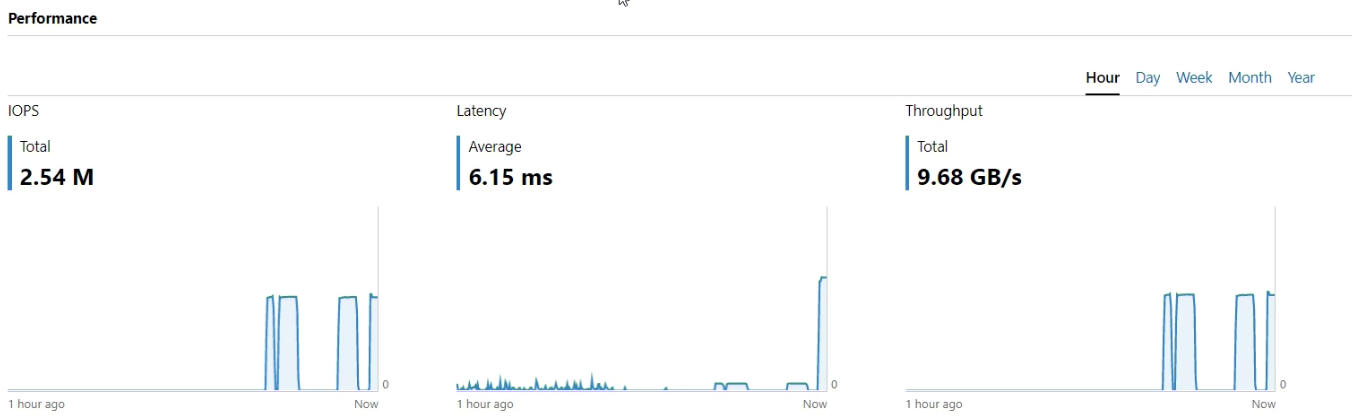
4K 100% Write – Expect to have much less IOPS then 100% Read
Die Daten werden bei einem Three-Way-Mirror noch auf 3 weiteren Fault Domains geschrieben, nicht zu vergessen…
.\Start-Workload.ps1 -DiskSpdpath "C:\Temp\DiskSpd" -w 100
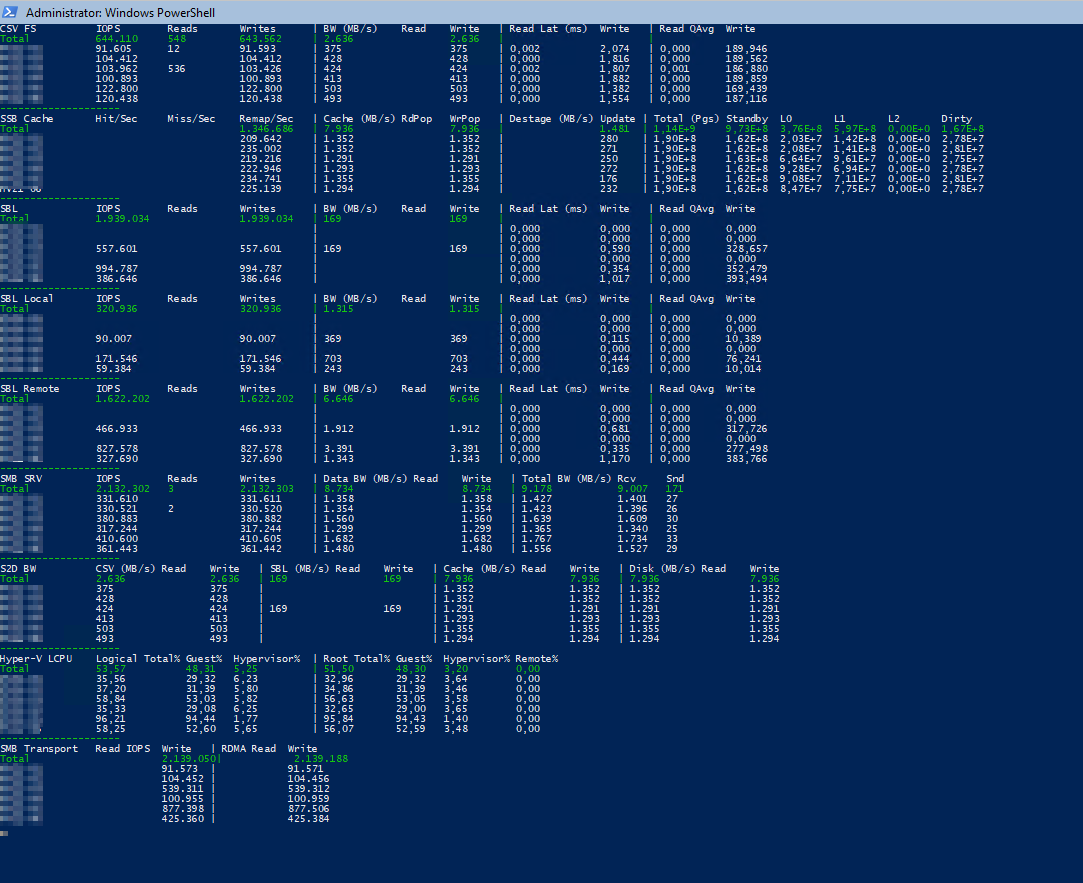
128K 100% Read – Maximize Throughput on Reads
Nun testen wir mit der Blockgröße von 128K und einer Queuetiefe von 32 (Outstanding IO’s). Hier haben wir dann zwar nicht unbedingt viele IO’s jedoch einen sehr hohen Durchsatz.
.\Start-Workload.ps1 -DiskSpdpath "C:\Temp\DiskSpd" -B 128K -o 32
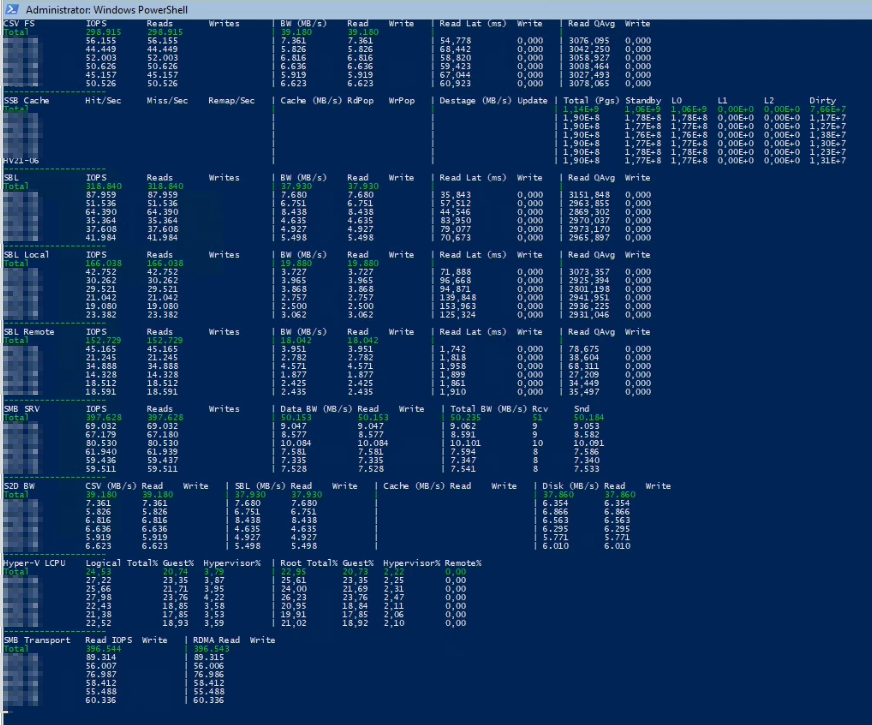
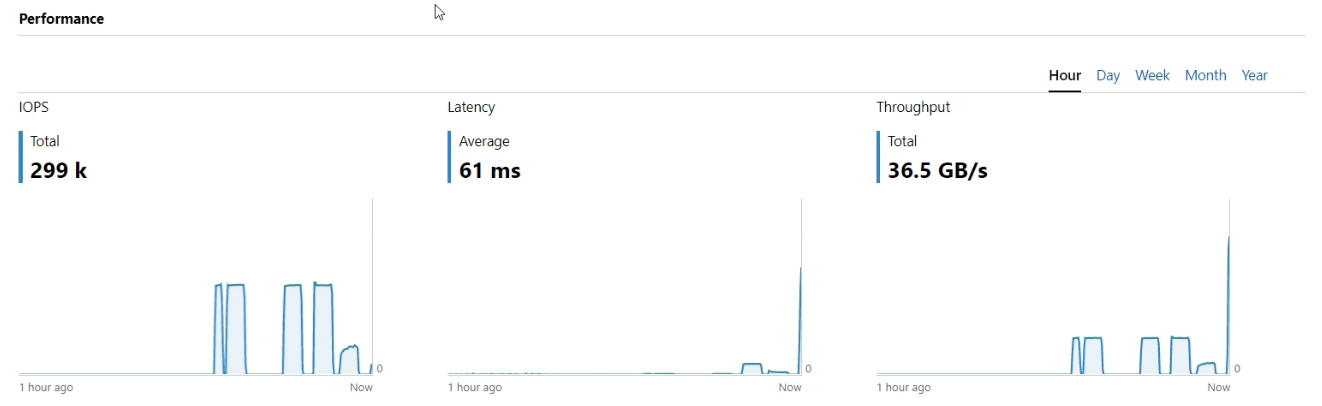

128K 100% Write- Maximize Throughput on Writes
Gleiches Spiel nur schreibend.
.\Start-Workload.ps1 -DiskSpdpath "C:\Temp\DiskSpd" -B 128K -o 32 -w 100

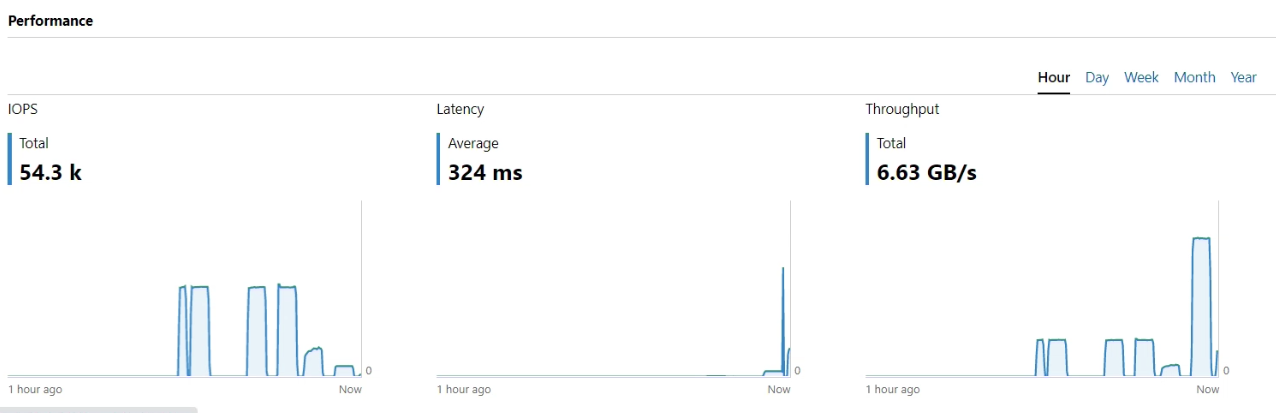
Netzwerkauslastung
Kombinierte Auslastung aller 25GbE Ports der beiden Switches (pro Switch):


In Summe kommen wir beim Lesen (4k) auf ungefähr 234 Gbit/s über alle Ports gerechnet. Das wären pro Server 39 Gbit/s die dann auf die 4 Karten verteilt werden.
Die Switche & Netzwerkkarten haben wir in Tests nur durch Livemigrationen höher ausgelastet bekommen. Ein guter Test ist eine Blanko VM mit 80% der maximal verfügbaren Ram-Menge des Hosts auszustatten (z.B. 500GB) und dann per Livemigration auf einen anderen Host zu migrieren. Das funktioniert per RDMA ziemlich gut und flott – speziell wenn die SMB Limits korrekt richtig gesetzt sind. In unserem Fall haben sich so VM’s mit 500 GB Arbeitsspeicher in wenigen Sekunden per Livemigration auf einen anderen Host migrieren lassen, was die Netzwerkkarten an ihr Limit bringt 😉
Auffälligkeiten
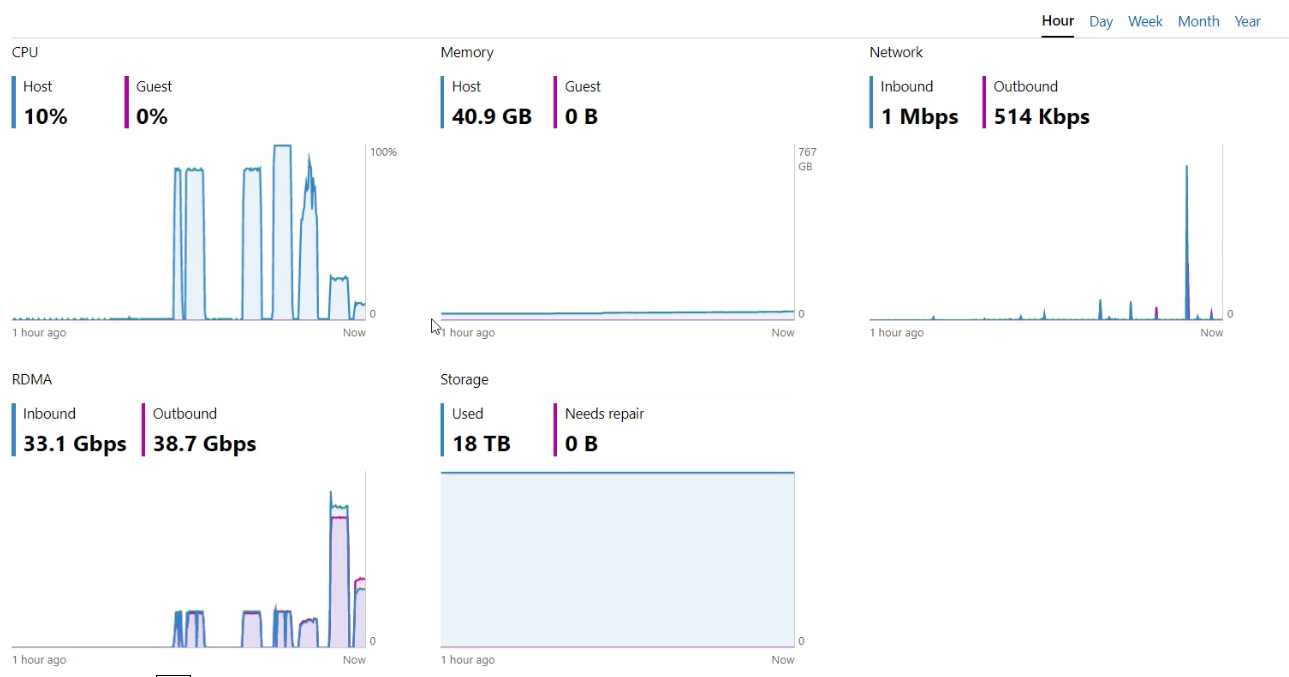
Bei kleinen Blockgrößen (4K) haben wir es immer geschafft die CPU’s der Hosts auf Vollast (80-100%) zu fahren, was bei 2 Sockel Xeon(R) Gold 6248R Systemen schon ganz ordentlich ist. Die CPU ist in diesem Fall der Flaschenhals – zumal noch kein anderer Workloud (VM’s) auf dem Cluster läuft. Im Realbetrieb ist hier natürlich eine etwas geringere Leistung zu erwarten. Bei den großen 128K Blöcken war die CPU nur zu ca. 20% ausgelastet. Hier haben wir gesehen, dass die SSD’s dann auch an ihre Grenzen gekommen, was sich auch gut an den höheren Latenzen auf SSD Ebene bestätigt hat.